ChatGPT is on fire, and the Chinese version is coming too?
◎ Science and Technology Daily reporter, Liu Yuanyuan
During this time, an artificial intelligence chat system called ChatGPT was like a spring thunder on the ground, suddenly exploding the network.
"Judging from the current general conversation experience, the biggest highlight of ChatGPT is its excellent intention recognition and language understanding ability, which makes people realize that the interaction ability of artificial intelligence has achieved leapfrog progress."Analysys wisdom institute senior analyst Chen Chen evaluation.
This magical human-computer interaction experience has aroused people’s enthusiasm for racking their brains to ask questions to ChatGPT, and brought it an amazing number of users: the system was launched by the American artificial intelligence research company OpenAI more than two months ago, and it has reached 100 million monthly active users in January this year. The user growth rate is unprecedented.
This product is very popular, and its important behind-the-scenes contributor is the technology known as the pre-trained model in the industry. In the face of the explosion of ChatGPT, domestic technology institutions and enterprises have "shined their swords".According to the latest news, the Chinese version of ChatGPT will be available to the public next month.
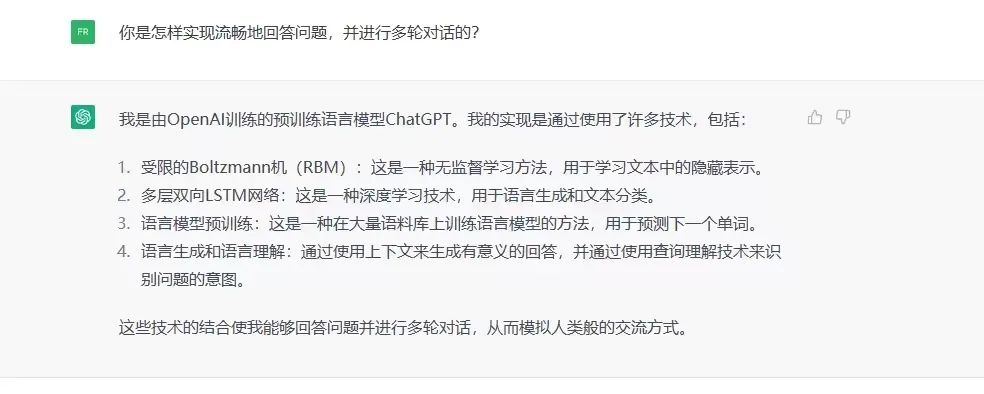
ChatGPT answers questions about itself.
The scale of parameters skyrockets from millions to hundreds of billions
"At present, pre-training technology is an important breakthrough in artificial intelligence research," explained Su Zhong, head of the Future Technology Center of Ali Research Institute.In traditional research methods, the cost of labeling has been an obstacle preventing artificial intelligence algorithms from pushing towards larger data sets, while pre-training techniques can train a large-scale deep learning model without relying on data annotations.
The Science and Technology Daily reporter learned that because data annotation is not required, pre-trained models can often use larger datasets, so they can choose larger model sizes – which has given rise to pre-trained large models.
"Compared with the previous artificial neural networks, the biggest difference of the pre-trained large model is that it is large enough, and the deep learning network has many layers, many connections, and many parameters." Zhang Jiaxing, a lecturer at the Cognitive Computing and Natural Language Research Center of IDEA Research Institute (Guangdong-Hong Kong-Macao Greater Bay Area Digital Economy Research Institute), introduced in an interview with reporters that the deep learning network around 2012 has only a few million parameters; the mainstream pre-trained model around 2018 reached 100 million parameters; the large-scale pre-trained model that has been proved to be very effective has hundreds of billions of parameters, which have been improved thousands of times in just a few years.
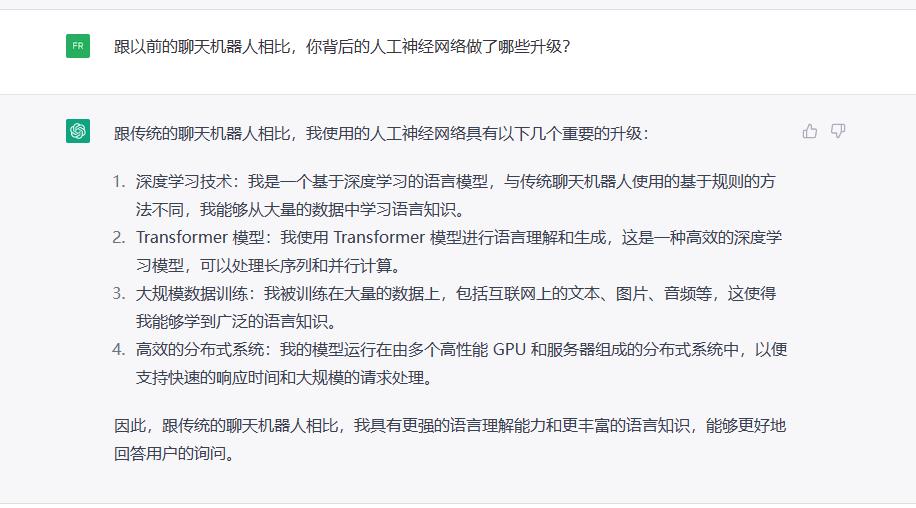
ChatGPT answers questions about itself.
Quantitative change leads to qualitative change. Su Zhong analyzed that in the evaluation of various techniques of the pre-trained model, the performance of the algorithm showed a rule:The larger the data size and the more parameters of the pre-trained model, the higher the output accuracy of the algorithm.
In addition to the large scale, Zhang Jiaxing said that the current pre-trained large model is very suitable for parallel training due to the use of new structural models. At the same time, in terms of training methods, the pre-training tasks of artificial neural networks are similar to "problem solving", such as removing a word or the first half of a sentence and letting the pre-trained model use massive big data to recover the sentence. In this way, the pre-trained model’s "problem solving" ability will get better and better. Moreover, on the basis of large language models, the introduction of instruction learning can far exceed the benefits of model fine-tuning. On this basis, human feedback can help the model better understand human intentions and receive information, and the human-machine dialogue will become more and more smooth.
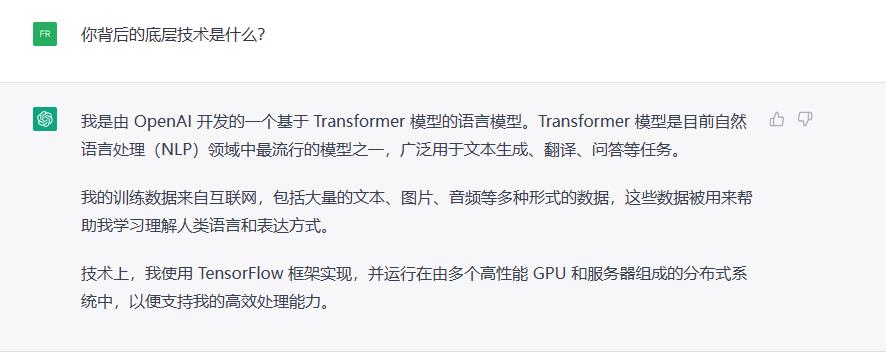
ChatGPT answers questions about itself.
"ChatGPT can be said to be a landmark artificial intelligence product in terms of underlying data, core technology, user experience, etc." Zhang Xiangyu, head of basic research at Megvii Research Institute, said,The core technology of ChatGPT is the artificial intelligence language model, the key is how to make the artificial intelligence model have logical reasoning ability, and how to make artificial intelligence learn the knowledge of the whole Internet.These ChatGPTs are basically achieved, thus making great breakthroughs in decision-making and knowledge.
Many domestic science and technology institutions have established a presence in related fields
According to foreign media reports, a number of foreign tech giants are investing heavily in pre-training models and artificial intelligence generated content (AIGC) track. The reporter learned that many domestic science and technology institutions and enterprises have laid out related fields.
Zhang Jiaxing told reporters that the IDEA Research Institute’s Cognitive Computing and Natural Language Research Center has been in this direction for a long time, and the center has the largest open-source model system in China – the list of gods. The 98 models that have been open-sourced are fully supporting the development of China’s AIGC, exploring the development of personalized and customizable models adapted to various fields, and supporting all natural language processing (NLP) tasks.
"It’s great to see the emergence of AIGC and ChatGPT in the tenth year of the rapid development of deep learning. Today, all these natural language processing tasks are being unified into the ChatGPT model. We are also integrating previous models and technologies to launch our ChatGPT-like model." Zhang Jiaxing said.

Source: Visual China
The reporter learned from Baidu that Baidu has invested in the development of related technologies similar to ChatGPT. The name of the project is determined to be ERNIE Bot. The English name is ERNIE Bot. It will be open to the public after the closed beta is completed in March. At present, ERNIE Bot is sprinting before going online.
"ChatGPT mainly involves natural language processing related technologies, which is one of the applications in the field of cognitive intelligence. iFLYTEK has a long-term and profound accumulation of technologies and applications in this direction." On the evening of February 8, iFLYTEK responded on the investor interaction platform that the company has open sourced a series of Chinese pre-trained language models in 6 categories and more than 40 general fields for the field of cognitive intelligence, and launched a generative pre-trained large model task in December last year. Artificial intelligence learning machine will become the first product to land this technology, and will be released at the product level in May this year.
In addition, 360 said on its investor interaction platform on February 7 that the company also plans to launch a prototype version of ChatGPT-like technology as soon as possible. "AIGC technology can assist in the improvement of digital security capabilities in addition to its application in search engines," 360 said.
(Science and Technology Daily reporters Cao Xiuying and Liu Yan also contributed to this article.)
Source: Science and Technology Daily, the pictures in the text are provided by the author unless indicated
Editor: Shen Wei (Internship)
Review: Yue Liang
Final Review: Wang Tingting